 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
OS-Oracle: A Comprehensive Framework for Cross-Platform GUI Critic Models
Dec 18, 2025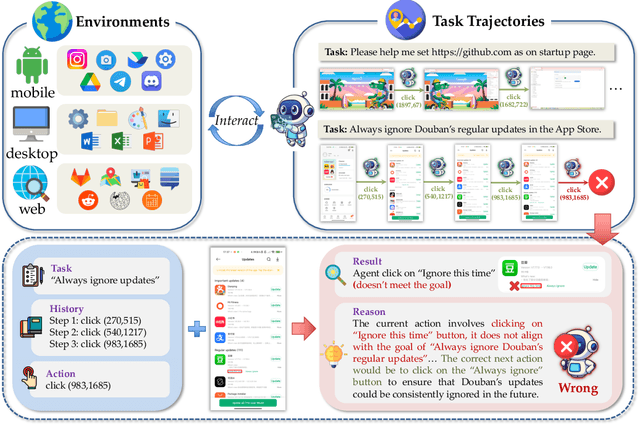
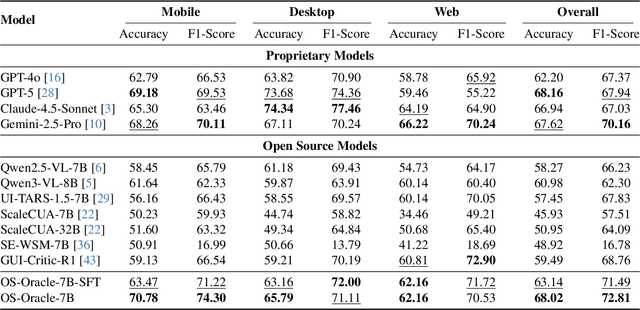
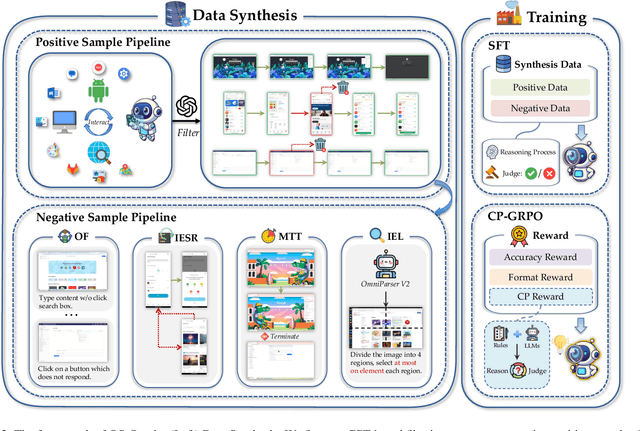
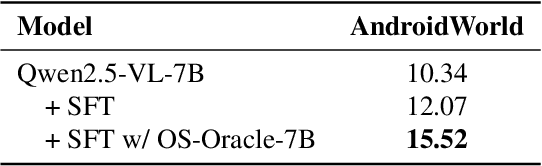
With VLM-powered computer-using agents (CUAs) becoming increasingly capable at graphical user interface (GUI) navigation and manipulation, reliable step-level decision-making has emerged as a key bottleneck for real-world deployment. In long-horizon workflows, errors accumulate quickly and irreversible actions can cause unintended consequences, motivating critic models that assess each action before execution. While critic models offer a promising solution, their effectiveness is hindered by the lack of diverse, high-quality GUI feedback data and public critic benchmarks for step-level evaluation in computer use. To bridge these gaps, we introduce OS-Oracle that makes three core contributions: (1) a scalable data pipeline for synthesizing cross-platform GUI critic data; (2) a two-stage training paradigm combining supervised fine-tuning (SFT) and consistency-preserving group relative policy optimization (CP-GRPO); (3) OS-Critic Bench, a holistic benchmark for evaluating critic model performance across Mobile, Web, and Desktop platforms. Leveraging this framework, we curate a high-quality dataset containing 310k critic samples. The resulting critic model, OS-Oracle-7B, achieves state-of-the-art performance among open-source VLMs on OS-Critic Bench, and surpasses proprietary models on the mobile domain. Furthermore, when serving as a pre-critic, OS-Oracle-7B improves the performance of native GUI agents such as UI-TARS-1.5-7B in OSWorld and AndroidWorld environments. The code is open-sourced at https://github.com/numbmelon/OS-Oracle.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
GS-Bias: Global-Spatial Bias Learner for Single-Image Test-Time Adaptation of Vision-Language Models
Jul 16, 2025Recent advances in test-time adaptation (TTA) for Vision-Language Models (VLMs) have garnered increasing attention, particularly through the use of multiple augmented views of a single image to boost zero-shot generalization. Unfortunately, existing methods fail to strike a satisfactory balance between performance and efficiency, either due to excessive overhead of tuning text prompts or unstable benefits from handcrafted, training-free visual feature enhancement. In this paper, we present Global-Spatial Bias Learner (GS-Bias), an efficient and effective TTA paradigm that incorporates two learnable biases during TTA, unfolded as the global bias and spatial bias. Particularly, the global bias captures the global semantic features of a test image by learning consistency across augmented views, while spatial bias learns the semantic coherence between regions in the image's spatial visual representation. It is worth highlighting that these two sets of biases are directly added to the logits outputed by the pretrained VLMs, which circumvent the full backpropagation through VLM that hinders the efficiency of existing TTA methods. This endows GS-Bias with extremely high efficiency while achieving state-of-the-art performance on 15 benchmark datasets. For example, it achieves a 2.23% improvement over TPT in cross-dataset generalization and a 2.72% improvement in domain generalization, while requiring only 6.5% of TPT's memory usage on ImageNet.
TextRefiner: Internal Visual Feature as Efficient Refiner for Vision-Language Models Prompt Tuning
Dec 11, 2024



Despite the efficiency of prompt learning in transferring vision-language models (VLMs) to downstream tasks, existing methods mainly learn the prompts in a coarse-grained manner where the learned prompt vectors are shared across all categories. Consequently, the tailored prompts often fail to discern class-specific visual concepts, thereby hindering the transferred performance for classes that share similar or complex visual attributes. Recent advances mitigate this challenge by leveraging external knowledge from Large Language Models (LLMs) to furnish class descriptions, yet incurring notable inference costs. In this paper, we introduce TextRefiner, a plug-and-play method to refine the text prompts of existing methods by leveraging the internal knowledge of VLMs. Particularly, TextRefiner builds a novel local cache module to encapsulate fine-grained visual concepts derivedfrom local tokens within the image branch. By aggregating and aligning the cached visual descriptions with the original output of the text branch, TextRefiner can efficiently refine and enrich the learned prompts from existing methods without relying on any external expertise. For example, it improves the performance of CoOp from 71.66 % to 76.94 % on 11 benchmarks, surpassing CoCoOp which introduces instance-wise features for text prompts. Equipped with TextRefiner, PromptKD achieves state-of-the-art performance and is efficient in inference. Our code is relesed at https://github.com/xjjxmu/TextRefiner
Advancing Multimodal Large Language Models with Quantization-Aware Scale Learning for Efficient Adaptation
Aug 07, 2024



This paper presents the first study to explore the potential of parameter quantization for multimodal large language models to alleviate the significant resource constraint encountered during vision-language instruction tuning. We introduce a Quantization-aware Scale LeArning method based on multimodal Warmup, termed QSLAW. This method is grounded in two key innovations: (1) The learning of group-wise scale factors for quantized LLM weights to mitigate the quantization error arising from activation outliers and achieve more effective vision-language instruction tuning; (2) The implementation of a multimodal warmup that progressively integrates linguistic and multimodal training samples, thereby preventing overfitting of the quantized model to multimodal data while ensuring stable adaptation of multimodal large language models to downstream vision-language tasks. Extensive experiments demonstrate that models quantized by QSLAW perform on par with, or even surpass, their full-precision counterparts, while facilitating up to 1.4 times reduction in VL tuning time and GPU consumption. Our code is released at https://github.com/xjjxmu/QSLAW.
UniPTS: A Unified Framework for Proficient Post-Training Sparsity
May 29, 2024
Post-training Sparsity (PTS) is a recently emerged avenue that chases efficient network sparsity with limited data in need. Existing PTS methods, however, undergo significant performance degradation compared with traditional methods that retrain the sparse networks via the whole dataset, especially at high sparsity ratios. In this paper, we attempt to reconcile this disparity by transposing three cardinal factors that profoundly alter the performance of conventional sparsity into the context of PTS. Our endeavors particularly comprise (1) A base-decayed sparsity objective that promotes efficient knowledge transferring from dense network to the sparse counterpart. (2) A reducing-regrowing search algorithm designed to ascertain the optimal sparsity distribution while circumventing overfitting to the small calibration set in PTS. (3) The employment of dynamic sparse training predicated on the preceding aspects, aimed at comprehensively optimizing the sparsity structure while ensuring training stability. Our proposed framework, termed UniPTS, is validated to be much superior to existing PTS methods across extensive benchmarks. As an illustration, it amplifies the performance of POT, a recently proposed recipe, from 3.9% to 68.6% when pruning ResNet-50 at 90% sparsity ratio on ImageNet. We release the code of our paper at https://github.com/xjjxmu/UniPTS.
Distribution-Flexible Subset Quantization for Post-Quantizing Super-Resolution Networks
May 12, 2023



This paper introduces Distribution-Flexible Subset Quantization (DFSQ), a post-training quantization method for super-resolution networks. Our motivation for developing DFSQ is based on the distinctive activation distributions of current super-resolution models, which exhibit significant variance across samples and channels. To address this issue, DFSQ conducts channel-wise normalization of the activations and applies distribution-flexible subset quantization (SQ), wherein the quantization points are selected from a universal set consisting of multi-word additive log-scale values. To expedite the selection of quantization points in SQ, we propose a fast quantization points selection strategy that uses K-means clustering to select the quantization points closest to the centroids. Compared to the common iterative exhaustive search algorithm, our strategy avoids the enumeration of all possible combinations in the universal set, reducing the time complexity from exponential to linear. Consequently, the constraint of time costs on the size of the universal set is greatly relaxed. Extensive evaluations of various super-resolution models show that DFSQ effectively retains performance even without fine-tuning. For example, when quantizing EDSRx2 on the Urban benchmark, DFSQ achieves comparable performance to full-precision counterparts on 6- and 8-bit quantization, and incurs only a 0.1 dB PSNR drop on 4-bit quantization. Code is at \url{https://github.com/zysxmu/DFSQ}
Bi-directional Masks for Efficient N:M Sparse Training
Feb 13, 2023We focus on addressing the dense backward propagation issue for training efficiency of N:M fine-grained sparsity that preserves at most N out of M consecutive weights and achieves practical speedups supported by the N:M sparse tensor core. Therefore, we present a novel method of Bi-directional Masks (Bi-Mask) with its two central innovations in: 1) Separate sparse masks in the two directions of forward and backward propagation to obtain training acceleration. It disentangles the forward and backward weight sparsity and overcomes the very dense gradient computation. 2) An efficient weight row permutation method to maintain performance. It picks up the permutation candidate with the most eligible N:M weight blocks in the backward to minimize the gradient gap between traditional uni-directional masks and our bi-directional masks. Compared with existing uni-directional scenario that applies a transposable mask and enables backward acceleration, our Bi-Mask is experimentally demonstrated to be more superior in performance. Also, our Bi-Mask performs on par with or even better than methods that fail to achieve backward acceleration. Project of this paper is available at \url{https://github.com/zyxxmu/Bi-Mask}.